Przykład budowy modelu DFD. Czym są DFD (diagramy przepływu danych) Temat: „Korzystanie z technologii DFD”
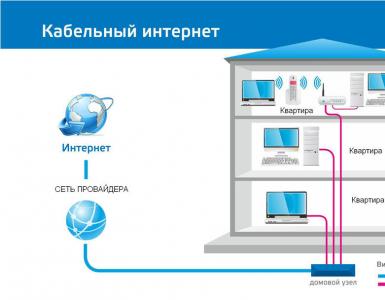
Rozważmy zbudowanie modelu DFD systemu informatycznego dla sieci sklepów sprzedających torby. Uzupełnijmy diagram IDEF0 zbudowany w pracy laboratoryjnej nr 1 o diagram DFD. Zbudujmy diagram DFD dla funkcji A4 „Analizuj pracę” Patrz ryc. 4.
Ryż. 4. Przykład diagramu DFD
Ćwiczenia
- Poznaj metodę DFD.
- Uzupełnij model funkcjonalny systemu informacyjnego, zbudowany w pracy laboratoryjnej nr 1, o diagram przepływu danych dla tych bloków funkcjonalnych IDEF0 modelu, dla których konieczne jest pokazanie ruchu danych.
- Odpowiedz na pytania bezpieczeństwa.
- Utwórz raport (strona tytułowa, zadanie, diagram DFD)
Pytania kontrolne
- Jakie procesy w systemie opisuje się za pomocą diagramów przepływu danych?
- Jakie są główne obiekty diagramów przepływu danych?
- Czy przy konstruowaniu diagramów DFD stosowana jest zasada dekompozycji?
- Miejsce, w którym strzałka zbliża się do bloków lub miejsce, w którym strzałka wychodzi z bloku, może być dowolne lub podlegać pewnym zasadom?
- W jaki sposób obiekt zostaje wyodrębniony w byt zewnętrzny?
Literatura
- Fedotova, D.E. Technologie CASE: Warsztat / D.E. Fedotova, Yu.D. Semenow, K.N. Czyżyk. - M.: Infolinia - Telekomunikacja, 2005. - 160 s.: il.
- Kalashyan, A.N. Strukturalne modele biznesowe: technologie DFD / A.N. Kalashyan, G.N. Kaljanow. - M.: Finanse i statystyka, 2003.
- Diagramy przepływu danych DFD. - http://www.proinfotech.ru/dmdlr2.htm.
- Metody modelowania procesów biznesowych. - http://www.jetinfo.ru/2004/10/1/article1.10.2004153.html.
Budowa diagramu dekompozycji w notacji DFD
Cel pracy:
- skonstruuj diagram dekompozycji w notacji DFD jednego z diagramów IDEF0 skonstruowanych w poprzednich laboratoriach
Diagramy przepływu danych (DFD) służą do opisu przepływu dokumentów i przetwarzania informacji. Podobnie jak IDEF0, DFD reprezentuje modelowany system jako sieć wzajemnie powiązanych działań. Można je zastosować jako dodatek do modelu IDEF0 w celu wyraźniejszego zobrazowania bieżących operacji obiegu dokumentów w korporacyjnych systemach przetwarzania informacji. Głównym celem DFD jest pokazanie, w jaki sposób każde zadanie przekształca swoje dane wejściowe w wyniki oraz ujawnienie relacji między tymi zadaniami.
Każdy diagram DFD może zawierać działania, podmioty zewnętrzne, strzałki (przepływy danych) i magazyny danych.
Pracuje. Prace przedstawiono w formie prostokątów z zaokrąglonymi narożnikami (ryc. 1), ich znaczenie pokrywa się ze znaczeniem prac IDEF0 i IDEF3. Podobnie jak działa IDEF3, mają wejścia i wyjścia, ale nie obsługują kontroli i mechanizmów takich jak IDEF0. Wszystkie aspekty pracy są sobie równe. Każde zadanie może mieć wiele strzałek wchodzących i wychodzących.

Rysunek 1. Praca w DFD
Podmioty zewnętrzne. Podmioty zewnętrzne reprezentują wejścia i/lub wyjścia z systemu. Pojedynczy podmiot zewnętrzny może jednocześnie dostarczać dane wejściowe (pełniąc funkcję dostawcy) i przyjmować dane wyjściowe (pełniąc funkcję odbiorcy). Podmiot zewnętrzny to obiekt materialny, taki jak klienci, personel, dostawcy, klienci, magazyn. Zdefiniowanie obiektu lub systemu jako podmiotu zewnętrznego oznacza, że znajduje się on poza granicami analizowanego systemu. Podmioty zewnętrzne są przedstawiane jako prostokąt z cieniem i zwykle znajdują się na krawędziach diagramu (ryc. 2).

Rysunek 2. Podmiot zewnętrzny w DFD
Strzałki (przepływy danych). Strzałki opisują ruch obiektów z jednej części układu do drugiej (stąd wynika, że diagram DFD nie może mieć strzałek granicznych). Ponieważ wszystkie boki DFD są równe, strzałki mogą zaczynać się i kończyć po dowolnej stronie prostokąta. Strzałki mogą być dwukierunkowe.
Magazyn danych. W przeciwieństwie do strzałek opisujących obiekty w ruchu, hurtownie danych przedstawiają obiekty w spoczynku (rysunek 3). Hurtownia danych to abstrakcyjne urządzenie służące do przechowywania informacji, które w dowolnym momencie można umieścić na dysku i odzyskać po pewnym czasie, a sposoby przechowywania i odtwarzania mogą być dowolne. Generalnie jest to prototyp przyszłej bazy danych i opis przechowywanych w niej danych musi odpowiadać modelowi informacyjnemu (Entity-RelationshipDiagram).

Rysunek 3. Przechowywanie danych w DFD
Dekompozycja pracy IDEF0 na diagram DFD. Podczas dekompozycji pracy IDEF0 na DFD należy wykonać następujące kroki:
- usuń wszystkie strzałki graniczne na diagramie DFD;
- stworzyć odpowiednie podmioty zewnętrzne i magazyny danych;
- utwórz strzałki wewnętrzne, zaczynając od elementów zewnętrznych zamiast strzałek granicznych;
- strzałki na tunelowanym diagramie IDEF0
Nie zawsze wygodnie jest ściśle trzymać się zasad notacji DFD, dlatego BPWin umożliwia tworzenie strzałek granicznych na diagramach DFD.
Budowa diagramu rozkładu. Rozłóżmy dzieło Wysyłka i dostawa schemat A0 „Działalność przedsiębiorstwa w zakresie montażu i sprzedaży komputerów i laptopów”. W tej pracy zidentyfikowaliśmy następujące prace podrzędne:
- dostawa niezbędnych komponentów – zajmuje się działaniami związanymi ze znalezieniem odpowiednich dostawców i zamówieniem u nich niezbędnych komponentów
- przechowywanie komponentów i zmontowanych komputerów
- wysyłka wyrobów gotowych – wszelkie czynności związane z pakowaniem, dokumentacją i faktyczną wysyłką wyrobów gotowych
Podkreślmy pracę Wysyłka i dostawa diagram A0 „Działalność przedsiębiorstwa w zakresie montażu i sprzedaży komputerów i laptopów”, kliknij na przycisk „GotoChildDiagram” na pasku narzędzi i wybierz notację DFD. Tworząc diagram podrzędny, BPWin przenosi strzałki graniczne pracy nadrzędnej, należy je usunąć i zastąpić obiektami zewnętrznymi. Strzałki mechanizmu, strzałki kontrolne „Zasady i procedury”, „Informacje zarządcze” i strzałka wyjścia „Raporty” na diagramie potomnym nie będą używane, aby nie zaśmiecać diagramu mniej istotnymi szczegółami. Pozostałe strzałki zastąpimy podmiotami zewnętrznymi - przycisk „ExternalReferenceTool” na pasku narzędzi, w oknie, które się pojawi, wybierz przełącznik „Strzałka” i wybierz żądaną nazwę z listy (ryc. 4):

Rysunek 4. Dodanie podmiotu zewnętrznego

Rysunek 5. Stanowiska pracy i podmioty zewnętrzne
Główną pracą jest tutaj „Przechowywanie komponentów i zmontowanych komputerów”. Do jego wpisu trafiają zmontowane komputery i komponenty otrzymane od dostawców, a także lista komponentów niezbędnych do złożenia komputerów. Efektem tej pracy będą niezbędne podzespoły (o ile są dostępne), lista brakujących podzespołów przeniesiona na wejście pracy „Dostawa niezbędnych podzespołów” oraz zmontowane komputery przekazane do wysyłki. Efektami pracy „Dostawa niezbędnych komponentów” i „Wysyłka gotowych produktów” będą odpowiednio zamówienia do dostawców i gotowe produkty.
Następnym krokiem jest określenie, jakie informacje są potrzebne do każdego zadania, tj. należy umieścić na schemacie hurtowni danych (rys. 6).

Rysunek 6. Ostateczny schemat rozkładu
Praca „Dostawa niezbędnych komponentów” współpracuje z informacjami o dostawcach oraz informacjami o złożonych zamówieniach u tych dostawców. Strzałka łącząca pracę z hurtownią danych „Lista dostawców” jest dwukierunkowa, ponieważ work może zarówno otrzymywać informacje o istniejących dostawcach, jak i wprowadzać dane o nowych dostawcach. Strzałka łącząca pracę z hurtownią danych „Lista zamówień” jest jednokierunkowa, gdyż praca wprowadza jedynie informacje o złożonych zamówieniach.
Praca „Magazynowanie komponentów i zmontowanych komputerów” współpracuje z informacjami o otrzymanych i wydanych komponentach oraz zmontowanych komputerach, dlatego strzałki łączące pracę z hurtowniami danych „Lista komponentów” i „Lista zmontowanych komputerów” są dwukierunkowe. Ponadto przy tej pracy przy odbiorze komponentów należy odnotować, że zamówienie do dostawców zostało zrealizowane. W tym celu łączy się go z magazynem danych „Lista zamówień” za pomocą jednokierunkowej strzałki. Należy pamiętać, że na diagramach DFD ten sam magazyn danych może zostać zduplikowany.
Wreszcie zadanie „Wysyłka produktów gotowych” musi przechowywać informacje o zrealizowanych wysyłkach. Aby to zrobić, wprowadź odpowiedni magazyn danych - „Dane przesyłki”.
Ostatnim krokiem jest tunelowanie strzałek pracy macierzystej (ryc. 7):

Rysunek 7. Diagram IDEF0 z tunelowanymi strzałkami dla zadania Wysyłka i zaopatrzenie.
- krótki opis dzieła podlegającego rozkładowi
- schemat rozkładu

Przykładowy diagram DFD procesu „Opracowanie specyfikacji technologicznej” z wykorzystaniem Bpwin
DFD), który zapewnia prawidłowy opis wyjść (reakcja systemu w postaci danych) pod zadanym wpływem na wejście systemu (dostarczanie sygnałów poprzez interfejsy zewnętrzne). Diagramy przepływu danych są głównym narzędziem modelowania wymagania funkcjonalne do projektowanego systemu.Podczas tworzenia diagramy przepływu danych stosowane są cztery podstawowe pojęcia: strumienie danych, procesy (prace) konwersji wejściowych strumieni danych na wyjściowe, podmioty zewnętrzne, urządzenia (magazyny) przechowywania danych.
Strumienie danych to abstrakcje używane do modelowania transferu informacji (lub komponentów fizycznych) z jednej części systemu do drugiej. Przepływy na diagramach są reprezentowane przez nazwane strzałki, których orientacja wskazuje kierunek przepływu informacji.
Zamiar proces(praca) polega na wytwarzaniu strumieni wyjściowych ze strumieni wejściowych zgodnie z działaniem określonym w nazwie procesu. Nazwa procesu musi zawierać czasownik w formie nieokreślonej, po którym następuje dopełnienie (np. „odbierz dokumenty do wysyłki produktów”). Każdy proces ma unikalny numer referencyjny na schemacie, który można wykorzystać w połączeniu z numerem diagramu w celu uzyskania unikalny indeks proces w całym modelu.
Przechowywanie danych (dysk) pozwala zdefiniować dane w określonych obszarach, które będą przechowywane w pamięci pomiędzy procesami. W efekcie hurtownia reprezentuje „wycinki” strumieni danych w czasie. Zawarte w nim informacje można wykorzystać w dowolnym momencie po ich otrzymaniu, a selekcję danych można przeprowadzić w dowolnej kolejności. Nazwa repozytorium musi identyfikować jego zawartość i być rzeczownikiem.
Podmiot zewnętrzny reprezentuje obiekt materialny poza kontekstem systemu, który jest źródłem lub odbiorcą danych systemowych. Jego nazwa musi zawierać rzeczownik, np. „magazyn towarów”. Zakłada się, że obiekty reprezentowane jako podmioty zewnętrzne, nie mogą być zaangażowane w żadne przetwarzanie.
Oprócz głównych elementów DFD zawiera słowniki danych i mini-specyfikacje.
Słowniki danych to katalogi wszystkich elementów danych występujących w DFD, w tym grupowych i indywidualnych przepływów danych, magazynów i procesów, a także wszystkich ich atrybutów.
Specyfikacje mini przetwarzania- opisać procesy DFD niższego poziomu. Tak naprawdę minispecyfikacje to algorytmy opisujące zadania realizowane przez procesy: zbiór wszystkich minispecyfikacji stanowi kompletną specyfikację systemu.
Proces budowania DFD rozpoczyna się od stworzenia tzw. podstawowego diagramu gwiazdy, który przedstawia modelowany proces i wszystkie podmioty zewnętrzne z kim wchodzi w interakcję. W przypadku złożonego procesu bazowego jest on natychmiast przedstawiany jako rozkład na szereg oddziałujących na siebie procesów. Kryteriami złożoności w tym przypadku są: obecność dużej liczby podmioty zewnętrzne, wielofunkcyjność systemu, jego rozproszony charakter. Podmioty zewnętrzne przydzielane są w odniesieniu do procesu głównego. Aby je określić, należy zidentyfikować dostawców i odbiorców procesu głównego, tj. wszystkie obiekty, które wchodzą w interakcję z procesem głównym. W tym momencie opisanie interakcji polega na wybraniu czasownika, który daje wyobrażenie o tym, w jaki sposób podmiot zewnętrzny wykorzystuje lub jest wykorzystywany przez proces leżący u jego podstaw. Przykładowo głównym procesem jest „rozliczanie wniosków obywateli”, podmiotem zewnętrznym są „obywatele”, opis interakcji to „składa wnioski i otrzymuje odpowiedzi”. Ten etap jest zasadniczo ważny, ponieważ to on wyznacza granice modelowanego układu.
Dla wszystkich podmioty zewnętrzne budowana jest tabela wydarzeń opisująca ich interakcję z głównym wątkiem. Tabela zdarzeń zawiera nazwę podmiotu zewnętrznego, zdarzenie, jego typ (typowy dla systemu lub wyjątkowy, realizowany w określonych warunkach) oraz reakcję systemu.
Następnym krokiem jest dekompozycja procesu głównego na zbiór wzajemnie powiązanych procesów wymieniających strumienie danych. Same przepływy nie są określone, określany jest jedynie charakter interakcji. Rozkład zostaje zakończony, gdy proces staje się prosty, tj.:
- proces ma dwa lub trzy wątki wejściowe i wyjściowe;
- proces ten można opisać jako przekształcanie danych wejściowych w dane wyjściowe;
- proces ten można opisać jako algorytm sekwencyjny.
Dla prostych procesów budowana jest minispecyfikacja – formalny opis algorytmu konwersji danych wejściowych na dane wyjściowe.
Mini-specyfikacja spełnia następujące wymagania: dla każdego procesu budowana jest jedna specyfikacja; specyfikacja jednoznacznie definiuje strumienie wejściowe i wyjściowe dla danego procesu; specyfikacja nie określa, w jaki sposób strumienie wejściowe są konwertowane na strumienie wyjściowe; specyfikacja odnosi się do istniejących elementów bez wprowadzania nowych; W miarę możliwości w specyfikacji zastosowano standardowe podejścia i operacje.
Po rozłożeniu procesu głównego budowana jest podobna tabela dla każdego podprocesu wydarzenia wewnętrzne.
Kolejnym krokiem po zdefiniowaniu pełnej tabeli zdarzeń jest alokacja strumienie danych, które są wymieniane pomiędzy procesami i podmioty zewnętrzne. Najprostszym sposobem ich wyizolowania jest analiza tabel zdarzeń. Zdarzenia są przekształcane w przepływy danych od inicjatora zdarzenia do żądanego procesu, a reakcje są przekształcane w odwrotny przepływ zdarzeń. Po skonstruowaniu strumieni wejściowych i wyjściowych, w ten sam sposób konstruowane są strumienie wewnętrzne. Aby je podkreślić, dla każdego z procesów wewnętrznych identyfikuje się dostawców i odbiorców informacji. Jeśli dostawca informacji lub konsument reprezentuje proces przechowywania informacji lub odpytywania informacji, wówczas wprowadzany jest magazyn danych, dla którego proces ten stanowi interfejs.
Po skonstruowaniu przepływów danych należy sprawdzić diagram pod kątem kompletności i spójności. Kompletność diagramu jest zapewniona, jeśli w systemie nie występują procesy „wiszące”, które nie są wykorzystywane w procesie konwersji strumieni wejściowych na strumienie wyjściowe. Spójność systemu zapewnia wdrożenie zbioru formalnych reguł dotyczących możliwych typów procesów: na schemacie łączącym dwa podmioty zewnętrzne– ta interakcja zostaje usunięta z analizy; żaden podmiot nie może bezpośrednio odbierać ani wysyłać informacji do magazynu danych - magazyn danych jest elementem pasywnym zarządzanym przez proces interfejsu; dwa magazyny danych nie mogą bezpośrednio wymieniać informacji - magazyny te muszą zostać połączone.
Zalety technik DFD nie różnią się od konwencjonalnych; brak pojęcia czasu, tj. brak analizy przedziałów czasowych przy konwersji danych (wszystkie ograniczenia czasowe muszą być zapisane w specyfikacji procesu).
Temat 8. Modelowanie przepływów danych
Postanowienia ogólne. 1
Model DFD..3
Rodzaje notacji DFD. 3
Struktura modelu DFD. 4
Podstawowe elementy DFD i ich przeznaczenie. 6
Wnioski: 11
Postanowienia ogólne
Istnieje legenda o tym, jak powstały DFD.
W latach dwudziestych konsultant reorganizujący biuro oznaczył każdego urzędnika kółkiem, a każdy dokument przekazywany między nimi strzałką. Korzystając z takiego diagramu, zaproponował schemat reorganizacji, w którym dwóch urzędników wymieniających wiele dokumentów siedziało w pobliżu, a urzędnicy z niewielką interakcją siedzieli w dużej odległości. Tak narodził się pierwszy model, będący diagramem blokowym – zwiastunem DFD. Od tego czasu minęło dużo czasu. Do okręgów i strzałek dodano nowe symbole, co zwiększyło siłę wyrazu zapisu. Pojawiły się nowe możliwości wykorzystania DFD do rozwiązywania problemów związanych z projektowaniem i rozwojem złożonych systemów oprogramowania. Wszystko to doprowadziło do tego, że DFD stało się jednym z bardzo popularnych zapisów podejścia strukturalnego.
Przykładowy diagram DFD pokazano na schemacie (ryc. 87).

Ryż. 87. Przykład diagramu DFD
Zanim zaczniemy przyglądać się składni DFD, należy szczególnie zauważyć, że w przeciwieństwie do SADT (IDEF0), DFD nie jest metodologią. Innymi słowy, DFD to po prostu zbiór ogólnie przyjętych notacji bez ścisłych ograniczeń dotyczących metod modelowania i stosowania otrzymanych modeli.
Podczas realizacji projektu tworzenia IS notację DFD można stosować jako główną notację modelowania funkcjonalnego, jednak często używa się jej jako dodatkowej w stosunku do IDEF0 (rys. 88).
Sieci informacyjne" href="/text/category/informatcionnie_seti/" rel="bookmark">przetwarzanie informacji. W przeciwieństwie do IDEF0, gdzie system jest uważany za wzajemnie połączone bloki funkcjonalne, a łuki reprezentują sztywne relacje, strzałki w DFD pokazują tylko to, co w jaki sposób obiekty (w tym dane) przemieszczają się z jednego zadania do drugiego DFD odzwierciedla zależności funkcjonalne wartości obliczonych w systemie, w tym wartości wejściowych, wartości wyjściowych i wewnętrznych magazynów danych.
Innymi słowy, DFD to wykres pokazujący przepływ wartości danych z ich źródeł poprzez procesy, które przekształcają je w odbiorców w innych obiektach.
DFD zawiera procesy przekształcające dane, strumienie danych przenoszące dane, aktywne obiekty wytwarzające i zużywające dane oraz magazyny danych, które pasywnie przechowują dane.
Jeśli mówimy o sile wyrazu notacji i porównujemy DFD z IDEF0, możemy powiedzieć, że brak takich pojęć, jak kontrola i mechanizm, gwałtownie zmniejsza potencjał DFD podczas analizy modelu, identyfikowania wąskich gardeł, znajdowania sposobów na ulepszenia itp. Wszystko to spowodowało, że DFD jest rzadko używany jako podstawowa notacja w projektach mających na celu przeprojektowanie procesów biznesowych, budowę systemu zarządzania jakością itp.
model DFD
Rodzaje notacji DFD
ODA.: W DFD (Data Flow Diagram) model systemu definiuje się jako hierarchię diagramów przepływu danych opisujących procesy przekształcania informacji od momentu ich wprowadzenia do systemu aż do wydania użytkownikowi końcowemu. Diagramy wyższych poziomów hierarchii – diagramy kontekstowe, wyznaczają granice modelu, definiują jego otoczenie (zewnętrzne wejścia i wyjścia) oraz główne rozpatrywane procesy. Diagramy kontekstowe są szczegółowe przy użyciu następujących poziomów diagramów.
Ponieważ DFD nie jest standardem, obecnie nie ma jednej notacji z jednoznacznie zdefiniowanymi elementami podstawowymi. Do reprezentowania modeli używa się wielu różnych notacji DFD. Najbardziej rozpowszechnione są notacje Geina-Sarsona i Jodana/de Marco (ryc. 89). Oprócz tych zapisów istnieją inne. Na przykład notacja stosowana w CA BPwin ma swoją własną charakterystykę. 
Ryż. 89. Najczęstsze notacje DFD
Pomimo istnienia kilku różnych notacji DFD, wszystkie różnią się jedynie zestawem prymitywów graficznych, które służą do budowy modeli funkcjonalnych.
Struktura modelu DFD
Hierarchię diagramów DF przedstawiono na schemacie (ryc. 90).
Koll" href="/text/category/koll/" rel="bookmark">zespoły programistów.
Po skonstruowaniu diagramów kontekstowych powstały model należy sprawdzić pod kątem kompletności danych wyjściowych o obiektach systemu oraz izolacji obiektów (brak powiązań informacyjnych z innymi obiektami).
Dla każdego podsystemu obecnego na diagramach kontekstowych jest on szczegółowo opisany za pomocą DFD. Z kolei każdy proces w DFD można opisać szczegółowo za pomocą DFD lub minispecyfikacji. Podczas opracowywania szczegółów należy przestrzegać zasady równoważenia. Istotą tej zasady jest to, że przy opisywania podsystemu lub procesu, diagram szczegółowy może zawierać tylko te komponenty (podsystemy, procesy, podmioty zewnętrzne, urządzenia do przechowywania danych), z którymi szczegółowy podsystem lub proces na platformie nadrzędnej ma połączenie informacyjne jako zewnętrzne schemat źródeł/odbiorników danych;
Minispecyfikacja (opis logiki procesu) powinna sformułować jego główne funkcje w taki sposób, aby w przyszłości specjalista realizujący projekt mógł je zrealizować lub opracować odpowiedni program.
Mini-specyfikacja to ostatni szczyt hierarchii DFD. Decyzję o dokończeniu uszczegółowienia procesu i wykorzystaniu minispecyfikacji podejmuje analityk w oparciu o następujące kryteria:
– proces ma stosunkowo małą liczbę strumieni danych wejściowych i wyjściowych (2-3 strumienie);
– umiejętność opisu transformacji danych przez proces w postaci algorytmu sekwencyjnego;
– proces realizuje pojedynczą funkcję logiczną polegającą na przetwarzaniu informacji wejściowych na dane wyjściowe;
– możliwość opisania logiki procesu za pomocą małej minispecyfikacji (nie więcej niż 20-30 linii).
Budując hierarchię DFD, do uszczegółowienia procesów należy przystąpić dopiero po ustaleniu zawartości wszystkich przepływów i dysków danych, co jest opisane za pomocą struktur danych. Struktury danych są zbudowane z elementów danych i mogą zawierać alternatywy, wystąpienia warunkowe i iteracje. Wystąpienie warunkowe oznacza, że dany komponent może nie występować w konstrukcji. Alternatywa oznacza, że konstrukcja może zawierać jeden z wymienionych elementów. Iteracja polega na wprowadzeniu dowolnej liczby elementów z określonego zakresu. Dla każdego elementu danych można określić jego typ (dane ciągłe lub dyskretne). W przypadku danych ciągłych można określić jednostkę miary (kg, cm itp.), zakres wartości, precyzję prezentacji i formę kodowania fizycznego. W przypadku danych dyskretnych można określić tabelę dopuszczalnych wartości.
Po zbudowaniu kompletnego modelu systemu należy go zweryfikować (sprawdzić pod kątem kompletności i spójności). W modelu kompletnym wszystkie jego obiekty (podsystemy, procesy, przepływy danych) muszą być szczegółowo opisane i uszczegółowione. Zidentyfikowane nieszczegółowe obiekty należy uszczegółowić, wracając do poprzednich etapów rozwoju. W spójnym modelu wszystkie przepływy danych i urządzenia do przechowywania danych muszą przestrzegać zasady przechowywania informacji: wszystkie dane, które gdzieś docierają, muszą zostać odczytane i wszystkie odczytane dane muszą zostać zapisane.
Podstawowe elementy DFD i ich przeznaczenie
Składnia DFD obejmuje cztery główne elementy:
- strumień danych;
- proces;
- składowanie;
- podmiot zewnętrzny.
Przyjrzyjmy się bliżej tym elementom.
Strumień danych
ODA.: Przepływ danych łączy wyjście obiektu (lub procesu) z wejściem innego obiektu (lub procesu). Reprezentuje pośrednie dane obliczeniowe. Przepływ danych jest przedstawiony jako strzałka pomiędzy producentem danych a konsumentem danych, oznaczona nazwami odpowiednich danych. Mówiąc najprościej, przepływy danych to mechanizmy używane do modelowania transferu informacji (lub komponentów fizycznych) z jednej części systemu do drugiej.
Przepływy na diagramach są reprezentowane przez strzałki (zwykle nazywane), których orientacja wskazuje kierunek przepływu informacji (ryc. 91).

Ryż. 91. Przepływ danych
W przeciwieństwie do łuków w IDEF0, przepływ danych w DFD może być nie tylko jednokierunkowy, ale także dwukierunkowy.
Proces
ODA.: Proces przekształca wartości danych.
Procesy reprezentują transformację strumieni danych wejściowych w strumienie wyjściowe zgodnie z określonym algorytmem. W prawdziwym życiu proces ten może być wykonywany przez jakiś dział organizacji, który przetwarza dokumenty wejściowe i wydaje raporty, przez indywidualnego pracownika, przez program zainstalowany na komputerze, przez specjalne urządzenie logiczne i tym podobne.
Celem procesu jest wytworzenie strumieni wyjściowych ze strumieni wejściowych zgodnie z działaniem określonym w nazwie procesu. Nazwa ta musi zawierać czasownik w formie nieokreślonej, po którym następuje dopełnienie (na przykład „wydać przepustkę”). Ponadto każdy proces musi mieć unikalny numer referencyjny na schemacie. Numeru tego można używać w połączeniu z numerem diagramu, aby zapewnić unikalny indeks procesu dla całego modelu.
Jak wspomniano wcześniej, ze względu na brak jednolitej normy obiekty DFD mogą mieć różne oznaczenia (ryc. 92).
Należy szczególnie podkreślić, że w przeciwieństwie do SADT, w DFD wszystkie strony bloku są równoważne (jest to oczywiste, jeśli spojrzeć na oznaczenie procesu w notacji Jodan/de Marco). Innymi słowy, w przeciwieństwie do diagramów IDEF0, diagramy DFD nie używają strzałek kontrolnych do wskazania zasad wykonania akcji i strzałek mechanizmu do wskazania wymaganych zasobów.
Bazy danych" href="/text/category/bazi_dannih/" rel="bookmark">bazy danych systemu informacyjnego organizacji.
ODA. 2: DATA STORAGE (STORAGE) umożliwia zdefiniowanie danych w określonych obszarach, które będą przechowywane w pamięci pomiędzy procesami. W efekcie hurtownia reprezentuje „wycinki” strumieni danych w czasie. Z informacji w nich zawartych można skorzystać w dowolnym momencie po ich zdefiniowaniu, a selekcję danych można przeprowadzić w dowolnej kolejności. Nazwa repozytorium musi identyfikować jego zawartość i być rzeczownikiem. W przypadku, gdy przepływ danych wchodzi lub wychodzi z hurtowni i jego struktura jest zgodna ze strukturą hurtowni, musi mieć tę samą nazwę, której nie trzeba pokazywać na diagramie.
Na schemacie miejsce przechowywania jest oznaczone tak, jak pokazano na schemacie (ryc. 93).
https://pandia.ru/text/80/146/images/image009_14.gif" szerokość="555" wysokość="183 src=">
Ryż. 94. Oznaczenie podmiotu zewnętrznego w różnych zapisach DFD
Przykład wykorzystania bytów zewnętrznych na diagramie kontekstu pokazano poniżej (ryc. 95). Podczas dekompozycji elementy zewnętrzne muszą zostać przeniesione do diagramu potomnego. CA BPwin nie ma możliwości automatycznego przenoszenia zewnętrznych podmiotów na diagram potomny, dlatego operację tę należy wykonać ręcznie.
https://pandia.ru/text/80/146/images/image011_14.gif" szerokość="567" wysokość="394 src=">
Ryż. 96. Przykład diagramu DFD
Wnioski:
Jak pokazano na początku tematu, DFD można uznać za główną notację modelowania funkcjonalnego w projektowaniu układów scalonych. Biorąc pod uwagę, że IDEF0 jest jednocześnie notacją opisującą systemy organizacyjno-ekonomiczne i produkcyjno-technologiczne, problem wyboru notacji pojawia się przy realizacji konkretnego projektu automatyzacji. Spróbujmy odpowiedzieć na pytanie: w jakim przypadku preferowany będzie DFD, a w jakim IDEF0?
Jak wynika z krótkiego przeglądu porównanych zapisów, DFD ma przewagę nad IDEF0 w zakresie reprezentacji struktur danych w modelu. Tak naprawdę zapis ten pozwala na zaprojektowanie bazy danych już na etapie modelowania funkcjonalnego.
Poważnymi wadami DFD są:
– po pierwsze, siła wyrazu notacji DFD okazuje się niewystarczająca przy analizie modelu, identyfikacji wąskich gardeł, poszukiwaniu sposobów usprawnień itp.;
– po drugie, DFD nie jest metodologią, co prowadzi do możliwości niejednoznacznej interpretacji wyników modelowania.
Wszystko to pozwala stwierdzić, że stosowanie DFD jako podstawowej notacji do modelowania funkcjonalnego jest uzasadnione, gdy mówimy o stworzeniu samodzielnie napisanego systemu oprogramowania i ma on na celu automatyzację istniejących procesów biznesowych bez ich optymalizacji, czyli gdy chcemy mówią o automatyzacji patchworku.
W przypadku złożonej automatyzacji, gdy najważniejsze nie jest programowanie, ale poszukiwanie rozwiązań optymalizujących biznes, notacja DFD nie może konkurować z IDEF0 i można ją traktować jedynie jako dodatkową.
Biorąc pod uwagę, że trendy IT wyraźnie wskazują na ślepy zaułek ścieżki „patchworkowej automatyzacji” i konieczność odchodzenia od samodzielnie napisanych systemów, staje się oczywiste, dlaczego wykorzystanie notacji DFD w działalności firm konsultingowych ulega drastycznemu ograniczeniu i odwrotnie, popularność IDEF0 gwałtownie rośnie.
Budując model funkcjonalny systemu, alternatywą dla metodologii () jest metodologia diagramy przepływu danych (Schematy przepływu danych, DFD). W odróżnieniu od tego, który jest ogólnie przeznaczony do projektowania systemów, DFD jest przeznaczony do projektowania systemów informatycznych. Skupienie tej metodologii na projektowaniu systemów zautomatyzowanych czyni ją wygodnym i korzystniejszym narzędziem przy budowaniu funkcjonalnego modelu TO-BE.
Konstruując diagramy rozróżnia się elementy zapisu graficznego przedstawione w tabeli. 6.1.
Tabela 6.1. Elementy notacji graficznej DFD
| Nazwa | Notacja Jordana | Notacja Geina-Sarsona |
| Strumień danych | ||
| Proces (system, podsystem) |  |
 |
| Przechowywanie danych | ||
| Podmiot zewnętrzny |  |
Strumień danych definiuje informację (obiekt materialny) przesyłaną poprzez połączenie ze źródła do odbiornika. Rzeczywistym strumieniem danych mogą być informacje przesyłane kablem między dwoma urządzeniami, listy wysyłane pocztą, taśmy magnetyczne lub dyskietki przesyłane z jednego komputera na drugi itp.
Każdy strumień danych ma nazwę odzwierciedlającą jego zawartość. Kierunek strzałki pokazuje kierunek przepływu danych. Czasami informacja może przemieszczać się w jednym kierunku, zostać przetworzona i wrócić do źródła. Sytuację tę można modelować albo dwoma różnymi przepływami, albo jednym – dwukierunkowym.
Zdefiniowanie jakiegoś obiektu, podmiotu lub systemu jako podmiotu zewnętrznego wskazuje, że znajduje się on poza granicami projektowanego systemu informacyjnego. Z tego powodu jednostki zewnętrzne są zwykle pokazywane tylko na kontekstowym diagramie DFD. W procesie analizy i projektowania niektóre byty zewnętrzne można w razie potrzeby przenieść na diagramy dekompozycji lub odwrotnie, część procesów (podsystemów) można przedstawić jako byt zewnętrzny.
Konstruowanie funkcjonalnego modelu DFD rozpoczyna się, podobnie jak w IDEF0, od opracowania diagramu kontekstu. Wyświetla proces główny (sam system jako całość) i jego powiązania ze środowiskiem zewnętrznym (podmiotami zewnętrznymi). Ta interakcja jest pokazana poprzez strumienie danych. Na diagramie kontekstowym można wyświetlić jednocześnie kilka głównych procesów lub podsystemów. Przykład diagramu kontekstowego dla rozważanego problemu pokazano na poniższym rysunku.

Ryż. 6.23. Schemat kontekstowy systemu wyznaczania dopuszczalnych prędkości (metodologia DFD)
Z diagramu wynika, że jako źródło danych wyjściowych do pracy systemu można wykorzystać bazę danych ARM-P (Track Service Workstation) lub SBD-P (Consolidated DB – Track Fragment), zawierającą niemal wszystkie niezbędne informacje o odcinkach dróg.
Jednocześnie system pozostawia możliwość ręcznego wprowadzania i regulacji. Pomimo tego, że bazy danych ARM-P czy SBD-P są podmiotami zewnętrznymi w stosunku do systemu, dla lepszego postrzegania są pokazane jako nośniki danych.
Dalszy proces projektowania polega na skonstruowaniu diagramów rozkładu, z których budowane są (przedstawiające urządzenie) tylko dla procesów lub podsystemów (systemów) .
Schemat dekompozycji pierwszego poziomu projektowanego układu przedstawiono na poniższym rysunku.

Ryż. 6.24. Diagram dekompozycji pierwszego poziomu (metodologia DFD)
Na tym rysunku brakuje nazw niektórych strumieni danych powiązanych z dyskami. Pozwala to wyeliminować powielanie etykiet i w efekcie zmniejszyć nasycenie diagramu.
Konstruując diagram dekompozycji, bloki systemu są pokazane w niektórych przypadkach jako procesy (nazwa zaczyna się od czasownika), w innych - jako podsystemy (nazwa zaczyna się od słowa „podsystem”). Ma to na celu zilustrowanie konwencji nazewnictwa bloków. Jednocześnie dekompozycję systemu można przedstawić albo za pomocą samych procesów, albo tylko podsystemów.
Diagram kontekstowy i diagram dekompozycji wykonano przy użyciu BPwin 4.0.
Decyzję o dokończeniu uszczegółowienia procesu i wykorzystaniu minispecyfikacji podejmuje projektant w oparciu o następujące kryteria:
Proces charakteryzuje się stosunkowo małą liczbą strumieni danych wejściowych i wyjściowych (2–3 strumienie);
Możliwość opisu procesów w formie prostego algorytmu;
Możliwość opisu logiki procesu za pomocą małej minispecyfikacji (nie więcej niż 20–30 linii).
Model DFD oprócz opisu funkcjonalnego aspektu systemu zawiera także informacje o aspektach informacyjnych i składowych. Zestaw urządzeń do przechowywania danych jest prototypem przyszłej bazy danych, tj. określa skład i strukturę informacji. Konstruowanie diagramów przy użyciu podsystemów jako bloków pokazuje skład i połączenia elementów przyszłego systemu.
6.12. Rozszerzenia DFD dla systemów czasu rzeczywistego
Systemy czasu rzeczywistego budowane są z reguły w oparciu o interakcję technologii komputerowej i różnych urządzeń fizycznych do gromadzenia informacji (czujniki, kamery, mikrofony itp.). Te pierwsze są dyskretnymi przetwornikami informacji, te drugie są głównie analogowe, tj. generowanie informacji w postaci ciągłego strumienia. Kolejną cechą takich systemów jest znaczne nastawienie na zarządzanie obiektami. Aby modelować zachowanie systemów czasu rzeczywistego, P. Ward i S. Mellor zaproponowali wykorzystanie dodatkowych elementów na DFD.